Overview
When you run a team in Agno, the response you get (TeamRunResponse) includes detailed metrics about the run. These metrics help you understand resource usage (like token usage and time), performance, and other aspects of the model and tool calls across both the team leader and team members. Metrics are available at multiple levels:- Per-message: Each message (assistant, tool, etc.) has its own metrics.
- Per-tool call: Each tool execution has its own metrics.
- Per-member run: Each team member run has its own metrics.
- Team-level: The
TeamRunResponseaggregates metrics across all team leader messages. - Session-level: Aggregated metrics across all runs in the session, for both the team leader and all team members.
Where Metrics Live
TeamRunResponse.metrics: Aggregated metrics for the team leader’s run, as a dictionary.TeamRunResponse.member_responses: Individual member responses with their own metrics.ToolExecution.metrics: Metrics for each tool call.Message.metrics: Metrics for each message (assistant, tool, etc.).Team.session_metrics: Session-level metrics for the team leader.Team.full_team_session_metrics: Session-level metrics including all team member metrics.
Example Usage
Suppose you have a team that performs some tasks and you want to analyze the metrics after running it. Here’s how you can access and print the metrics:Team Leader Metrics
Team Leader Message Metrics
This section provides metrics for each message response from the team leader. All “assistant” responses will have metrics like this, helping you understand the performance and resource usage at the message level.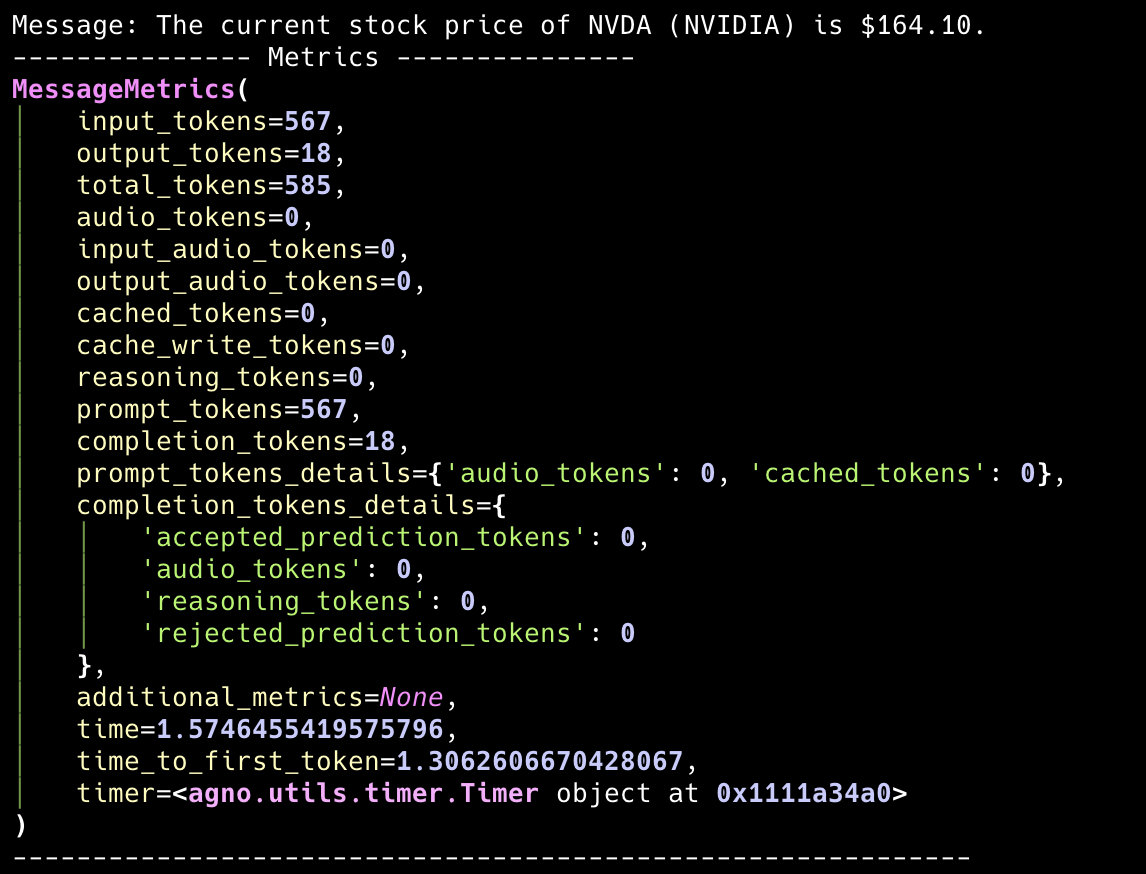
Aggregated Team Leader Metrics
The aggregated metrics provide a comprehensive view of the team leader’s run. This includes a summary of all messages and tool calls, giving you an overall picture of the team leader’s performance and resource usage.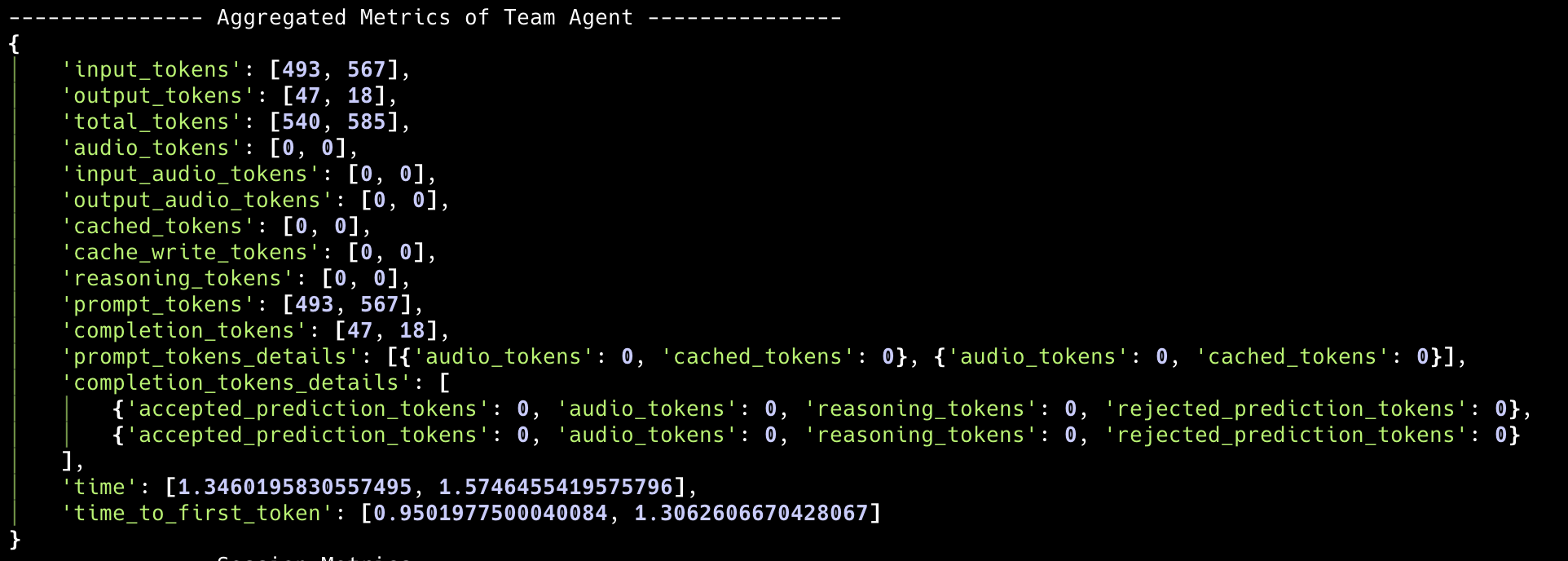
Team Member Metrics
Individual Member Metrics
Each team member has their own metrics that can be accessed throughteam.run_response.member_responses. This allows you to analyze the performance of individual team members.
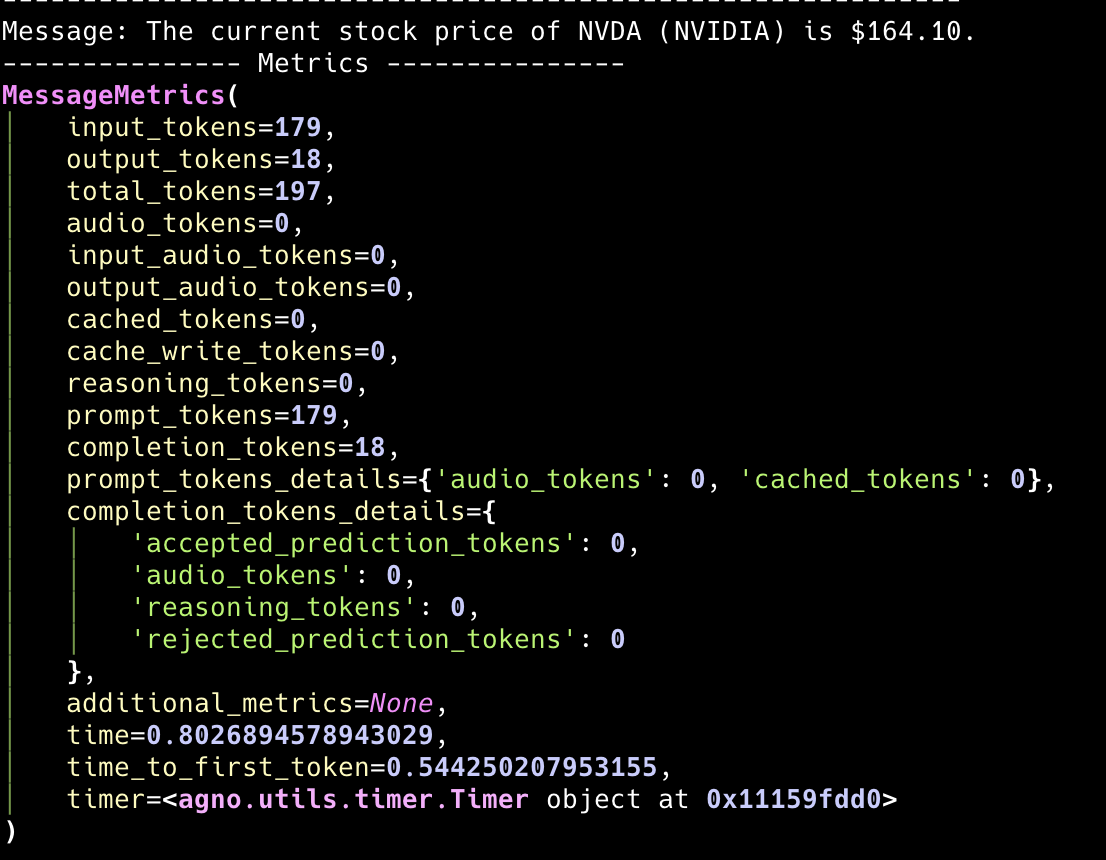
Member Response Structure
Each member response contains:messages: List of messages with individual metricsmetrics: Aggregated metrics for that member’s runtools: Tool executions with their own metrics
Session-Level Metrics
Team Leader Session Metrics
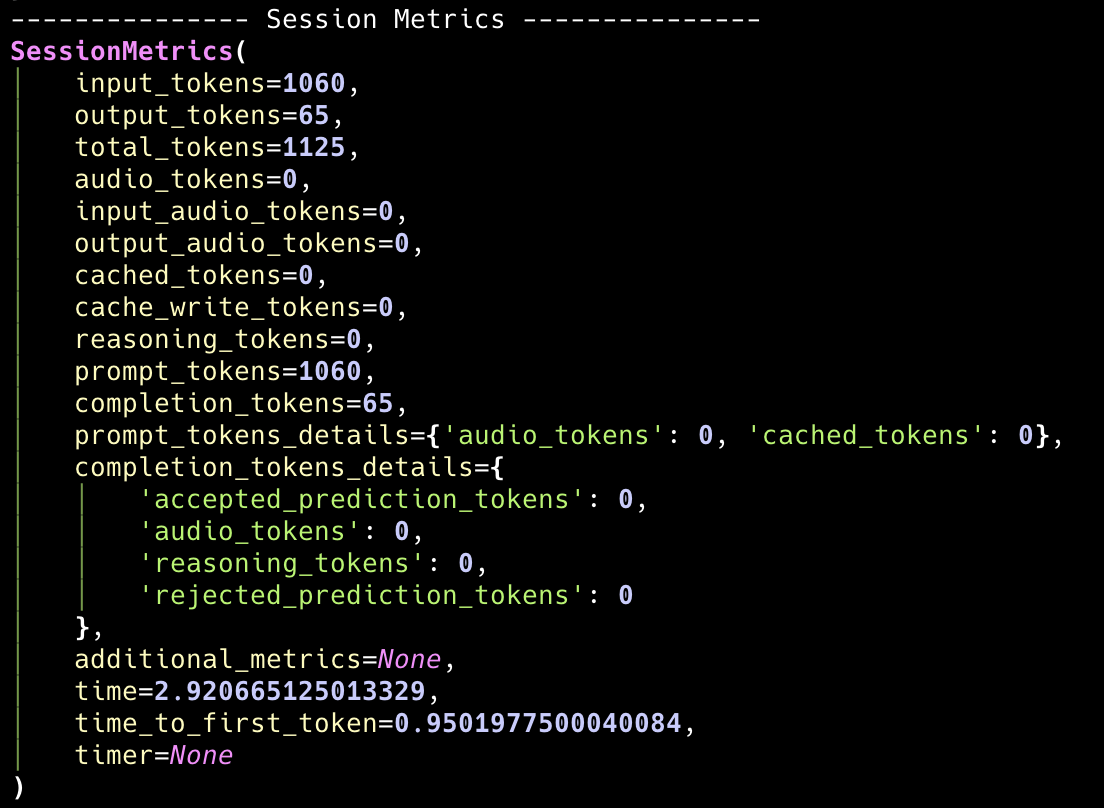
Theteam.session_metrics provides aggregated metrics across all runs in the session for the team leader only.
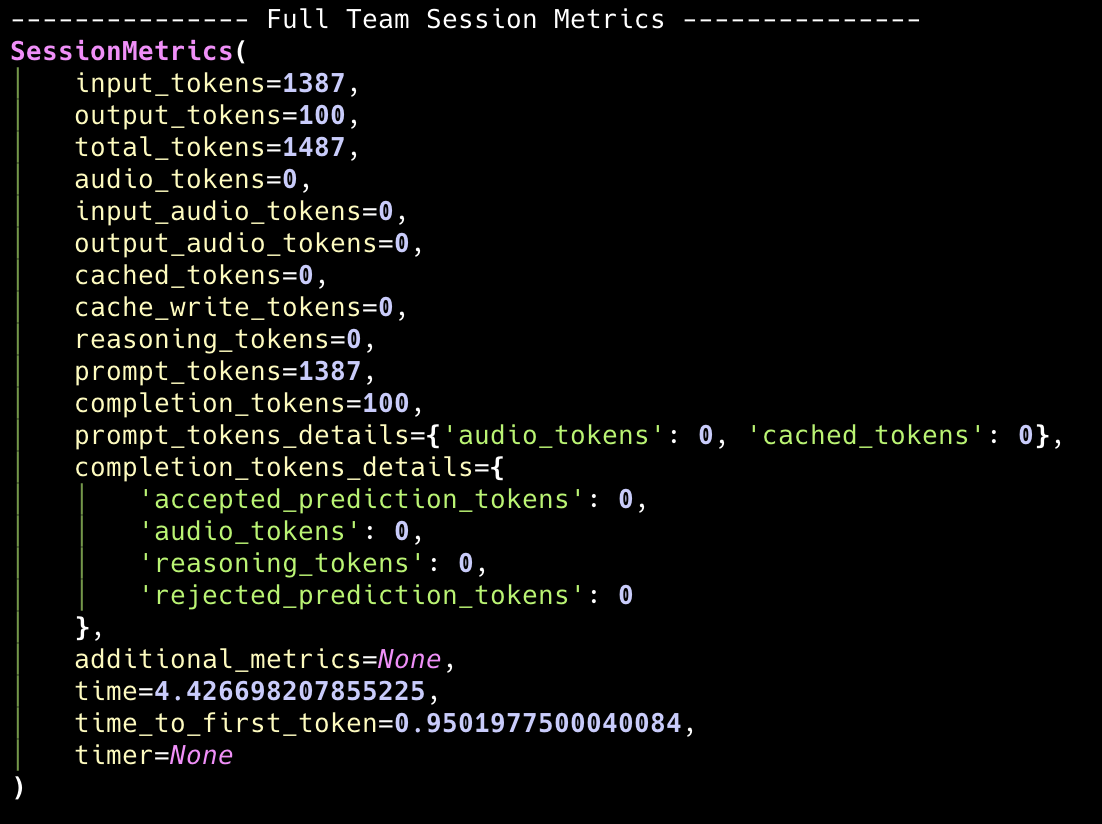
Full Team Session Metrics
Theteam.full_team_session_metrics provides comprehensive metrics that include both the team leader and all team members across all runs in the session.
How Metrics Are Aggregated
Team Leader Level
- Per-message: Each message (assistant, tool, etc.) has its own metrics object.
- Run-level:
TeamRunResponse.metricsis a dictionary where each key (e.g., input_tokens) maps to a list of values from all assistant messages in the run. - Session-level:
team.session_metricsaggregates metrics across all team leader runs in the session.
Team Member Level
- Per-member: Each team member has their own metrics tracked separately.
- Member aggregation: Individual member metrics are aggregated within their respective
RunResponseobjects. - Full team aggregation:
team.full_team_session_metricscombines metrics from the team leader and all team members.
Cross-Member Aggregation
- Session-level:
team.full_team_session_metricsprovides a complete view of all token usage and performance metrics across the entire team.
Accessing Member Metrics Programmatically
You can access individual member metrics in several ways:Metrics Comparison
| Metric Level | Access Method | Description |
|---|---|---|
| Team Leader Run | team.run_response.metrics | Aggregated metrics for the current run |
| Team Leader Session | team.session_metrics | Aggregated metrics across all team leader runs |
| Individual Member | member_response.metrics | Metrics for a specific team member’s run |
| Full Team Session | team.full_team_session_metrics | Complete team metrics including all members |
MessageMetrics Params
| Field | Description |
|---|---|
| input_tokens | Number of tokens in the prompt/input to the model. |
| output_tokens | Number of tokens generated by the model as output. |
| total_tokens | Total tokens used (input + output). |
| prompt_tokens | Tokens in the prompt (same as input_tokens in the case of OpenAI). |
| completion_tokens | Tokens in the completion (same as output_tokens in the case of OpenAI). |
| audio_tokens | Total audio tokens (if using audio input/output). |
| input_audio_tokens | Audio tokens in the input. |
| output_audio_tokens | Audio tokens in the output. |
| cached_tokens | Tokens served from cache (if caching is used). |
| cache_write_tokens | Tokens written to cache. |
| reasoning_tokens | Tokens used for reasoning steps (if enabled). |
| prompt_tokens_details | Dict with detailed breakdown of prompt tokens (used by OpenAI). |
| completion_tokens_details | Dict with detailed breakdown of completion tokens (used by OpenAI). |
| additional_metrics | Any extra metrics provided by the model/tool (e.g., latency, cost, etc.). |
| time | Time taken to generate the message (in seconds). |
| time_to_first_token | Time until the first token is generated (in seconds). |
Note: Not all fields are always present; it depends on the model/tool and the run.
SessionMetrics Params
| Field | Description |
|---|---|
| input_tokens | Number of tokens in the prompt/input to the model. |
| output_tokens | Number of tokens generated by the model as output. |
| total_tokens | Total tokens used (input + output). |
| prompt_tokens | Tokens in the prompt (same as input_tokens in the case of OpenAI). |
| completion_tokens | Tokens in the completion (same as output_tokens in the case of OpenAI). |
| audio_tokens | Total audio tokens (if using audio input/output). |
| input_audio_tokens | Audio tokens in the input. |
| output_audio_tokens | Audio tokens in the output. |
| cached_tokens | Tokens served from cache (if caching is used). |
| cache_write_tokens | Tokens written to cache. |
| reasoning_tokens | Tokens used for reasoning steps (if enabled). |
| prompt_tokens_details | Dict with detailed breakdown of prompt tokens (used by OpenAI). |
| completion_tokens_details | Dict with detailed breakdown of completion tokens (used by OpenAI). |
| additional_metrics | Any extra metrics provided by the model/tool (e.g., latency, cost, etc.). |
| time | Time taken to generate the message (in seconds). |
| time_to_first_token | Time until the first token is generated (in seconds). |
Note: Not all fields are always present; it depends on the model/tool and the run.